Kaldi 数据准备 数据准备这块涉及的脚本很杂且每一个样例的脚本都区别很大,但本质上每一个任务需要准备的数据类似
/mnt/users/xin_zhang/github_project/kaldi/egs/librispeech/s5
1. 音频及文本表单数据 这些数据通常放在data/train 目录下
1.1 必要文件 最重要的文件,也就是每一个项目都必须准备的数据,也是需要自己创建的文件包括:
text
text文件包含每个utterance对应的transcript。第一列是utterance-id,后面是分词 后的transcript。utterance-id可以是任意字符串,但是要求唯一。但如果需要告诉kaldi这句话是哪个speaker说的,通常的约定是把speaker-id作为utterance-id的前缀。
1 2 3 [xin_zhang@unn01 train_clean_100] head -2 text103 -1240 -0000 CHAPTER ONE MISSUS RACHEL LYNDE IS SURPRISED MISSUS RACHEL LYNDE LIVED JUST WHERE THE AVONLEA MAIN ROAD DIPPED DOWN INTO A LITTLE HOLLOW FRINGED WITH ALDERS AND LADIES EARDROPS AND TRAVERSED BY A BROOK 103 -1240 -0001 THAT HAD ITS SOURCE AWAY BACK IN THE WOODS OF THE OLD CUTHBERT PLACE IT WAS REPUTED TO BE AN INTRICATE HEADLONG BROOK IN ITS EARLIER COURSE THROUGH THOSE WOODS WITH DARK SECRETS OF POOL AND CASCADE BUT BY THE TIME IT REACHED LYNDE'S HOLLOW IT WAS A QUIET WELL CONDUCTED LITTLE STREAM
wav.scp
这个文件告诉kaldi每个utterance-id对应的录音文件的位置。第一列是utterance-id(或者recording-id,参考segments),第二列是录音文件的路径。kaldi实际要求的是extended-filename,这个extended-filename可以是一个wav文件,但是也可以是一个命令,这个命令能产生一个wav文件(用管道符 “|” 进行处理)。
1 2 3 4 [xin_zhang@unn01 train_clean_100] head -2 wav.scp103 -1240 -0000 flac -c -d -s /mnt/u sers/xin_zhang/gi thub_project/kaldi/ egs/librispeech/ data/LibriSpeech/ train-clean-100 /103/ 1240 /103 -1240 -0000 .flac |103 -1240 -0001 flac -c -d -s /mnt/u sers/xin_zhang/gi thub_project/kaldi/ egs/librispeech/ data/LibriSpeech/ train-clean-100 /103/ 1240 /103 -1240 -0001 .flac |
utt2spk
这个文件告诉kaldi,utterance-id对应哪个speaker-id。speaker-id不一定要求准确的对应到某个人,只要大致准确就行。如果我们不知道说话人是谁,那么我们可以把speaker-id设置成utterance-id,这是比较安全的做法。但最好不要把未知说话人的句子都对应到一个“全局”的speaker,这样的坏处是会使得cepstral mean normalization变得无效。
1 2 3 4 [xin_zhang@unn01 train_clean_100] head -3 utt2spk-1240 -0000 103-1240 -1240 -0001 103-1240 -1240 -0002 103-1240
spk2utt
这个文件和utt2spk反过来,它存储的是speaker和utterance的对应关系,这是一对多的关系,可以使用脚本来得到:
1 utils /utt2 spk_to_spk2 utt.pl data/train/utt2 spk > data/train/spk2 utt
1.2 非必需文件 segments
这个文件对应的是wav.scp
1 2 3 4 s5 # head -3 data/train/segmentssw02001 -A_000098 -001156 sw02001 -A 0 .98 11 .56 sw02001 -A_001980 -002131 sw02001 -A 19 .8 21 .31 sw02001 -A_002736 -002893 sw02001 -A 27 .36 28 .93
这个文件的每行为4列,第1列是utterance-id,第2列是recording-id。如果有segments文件,那么wav.scp第一列就不是utterance-id而变成recording-id了。recording-id表示一个录音文件的id,而一个录音文件可能包含多个utterance。因此第3列和第4列告诉kaldi这个utterance-id在录音文件中开始和介绍的实际。比如上面的例子,utterance “sw02001-A_000098-001156”在sw02001-A这个录音文件里,开始和结束时间分别是0.98秒到11.56秒。
spk2gender
这个文件不是必须的,它说明说话人的性别。
1 2 3 4 [xin_zhang@unn01 train_clean_100] head -3 spk2gender-1240 f-1241 f-121119 m
utt2dur
这个文件对应wav.scp里每个音频的长度
1 2 3 4 [xin_zhang@unn01 train_clean_100] head -3 utt2dur-1240 -0000 14.085-1240 -0001 15.945-1240 -0002 13.945
utt2num_frames
这个文件对应wav.scp里每个音频的帧数
1 2 3 4 [xin_zhang@unn01 train_clean_100] head -3 utt2num_frames-1240 -0000 1407-1240 -0001 1593-1240 -0002 1393
2. 语言模型及词典数据 2.1 lang 一般最终使用的词典数据都放置于data/lang 路径下, 此处在librispeech中路径为data/lang_nosp:
1 2 [xin_zhang@unn01 s5] ls data/lang_nosp/.fst L.fst oov.int oov.txt phones phones.txt topo words.txt
lang目录的内容
phones.txt和words.txt,这两个文件都是符号表(符号到ID的映射),这是OpenFst需要的格式。
1 2 3 4 5 6 7 8 9 10 11 12 [xin_zhang@unn01 lang_nosp] head -5 phones.txt<eps> 0@unn01 lang_nosp] head -5 words.txt<eps> 0<SPOKEN_NOISE> 2<UNK> 3
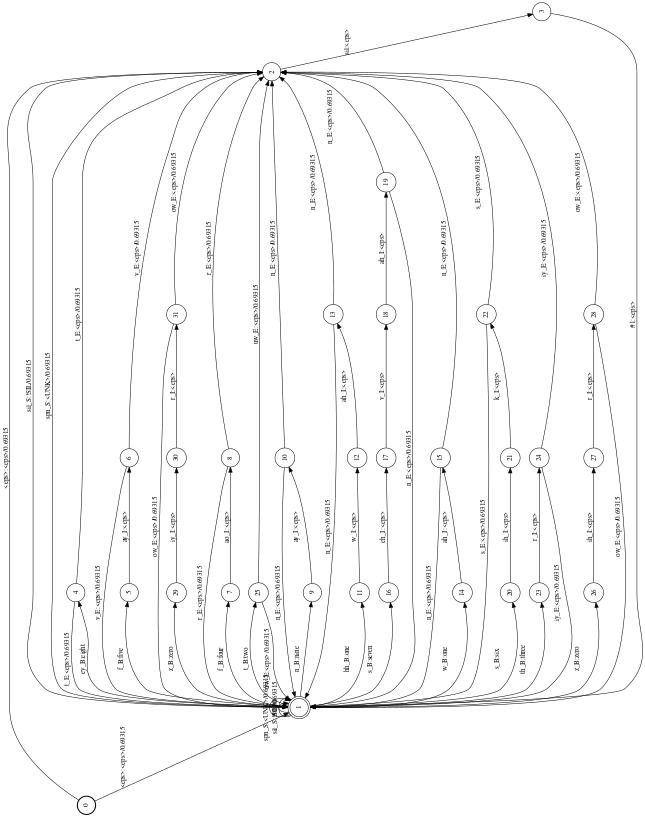
L.fst是lexicon的WFST格式,L_disambig.fst引入了#1等消歧符号,可以用openfst的工具输出可视化图片
1 2 3 4 fstdraw --isymbols=phones.txt --osymbols=words.txt L .L .L_disambig .L_disambig .L .L .L_disambig .L_disambig .
oov.txt里是未登录词(Out of Vocabulary Words)。
1 2 [xin_zhang@unn01 lang_nosp] cat oov.txt<UNK>
这里把所有未登录词映射成一个特殊词。比较重要的一点是这个词通常只有一个特殊的phone,而且这个特殊的phone用来对应所有的”garbage phone”,比如把各种噪声、特殊声音都用这个phone来表示:
1 2 [xin_zhang@unn01 lang] grep -w <UNK> data/local/ dict/lexicon.txt<UNK> spn
topo 这个文件是HMM的拓扑结构定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 [xin_zhang@unn01 lang_nosp] cat topo 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 0 <PdfClass> 0 <Transition> 0 0.75 <Transition> 1 0.25 </State> 1 <PdfClass> 1 <Transition> 1 0.75 <Transition> 2 0.25 </State> 2 <PdfClass> 2 <Transition> 2 0.75 <Transition> 3 0.25 </State> 3 </State> 2 3 4 5 6 7 8 9 10 0 <PdfClass> 0 <Transition> 0 0.25 <Transition> 1 0.25 <Transition> 2 0.25 <Transition> 3 0.25 </State> 1 <PdfClass> 1 <Transition> 1 0.25 <Transition> 2 0.25 <Transition> 3 0.25 <Transition> 4 0.25 </State> 2 <PdfClass> 2 <Transition> 1 0.25 <Transition> 2 0.25 <Transition> 3 0.25 <Transition> 4 0.25 </State> 3 <PdfClass> 3 <Transition> 1 0.25 <Transition> 2 0.25 <Transition> 3 0.25 <Transition> 4 0.25 </State> 4 <PdfClass> 4 <Transition> 4 0.75 <Transition> 5 0.25 </State> 5 </State>
phone 1-10是各种静音和噪声,普通的phone通常都是3状态的,而silence这里是5状态的,因为silence通常更长。这么多phone的原因是word-position的依赖。
1 2 3 4 AA_B 11 AA_E 12 AA_I 13 AA_S 14
第一个是AA_B表示处于词开始的ah,而AA_E表示它是一个词的最后一个音素。如果一个词由三个以上音素组成,那么中间的都是用_I表示。如果一个词只有一个音素,那么用 _S表示,这种表示方法在NLP的序列标注里也非常常见。
lang目录其实是比较复杂的,因为phones是一个目录:
1 2 3 4 [xin_zhang@unn01 s5] ls data/lang_nosp/phones.int context_indep.int disambig.int extra_questions.txt nonsilence.txt optional_silence.txt sets.int silence.int wdisambig.txt word_boundary.txt .txt context_indep.txt disambig.txt nonsilence.csl optional_silence.csl roots.int sets.txt silence.txt wdisambig_words.int .csl disambig.csl extra_questions.int nonsilence.int optional_silence.int roots.txt silence.csl wdisambig_phones.int word_boundary.int
phones子目录包括phone set的很多信息。它下面有一些同名但是不同后缀的文件,有3种后缀:txt、int和csl。其中txt是人可读的格式。我们不需要自己来生成这些文件,Kaldi提供了一个通用的utils/prepare_lang.sh,只需要我们为这个脚本提供一些参数。
data/lang/phones
这个目录下的很多文件都是定义不同的phone set,它们通常包含三种格式且包含相同的信息,txt是音素文本文件,int是对应的音素索引,csl讲音素索引合并成一行,下面只介绍txt格式的文件:
context_indep.txt
1 2 3 4 5 6 [xin_zhang@unn01 phones] head context_indep.txt
这个文件的内容是上下文无关的phone,对于这些phone,后续模型训练时构建的决策树聚类时不考虑上下文。
silence.txt和nonsilence.txt
这两个文件分别包含silence的phone和非silence的phone,并且它们是没有交集的,而且它们的并集是所有的phone。在这个例子里,silence.txt和context_indep.txt是恰巧一样的。所谓的非silence的phone,kaldi认为是可以对它进行各种线性变换的phone。比如全局的LDA和MLLT;或者说话人相关的自适应变换比如fMLLR。silence是不值得做这些变换的(比如认为不同人说同一个”a”是有差别的,但是认为静音对于所有人都是一样的,比如背景噪音是没有必要根据说话人做什么变换的)。kaldi把所有的silence、背景噪声和发音噪声都作为”silence”的phone,而其它”真正”的音素当成非silence phone。
1 2 3 4 5 6 7 8 9 10 [xin_zhang@unn01 phones] head -3 nonsilence.txt silence.txt=> nonsilence.txt <== => silence.txt <==
disambig.txt
这个文件包含所有的消岐符号,消歧符号出现了phones.txt里,kaldi把它当成phone。关于消歧符号请参考http://kaldi-asr.org/doc/graph.html#graph_disambig。
1 2 3 4 [xin_zhang@unn01 phones] head -3 disambig.txt#0 #1 #2
optional_silence.txt
1 2 [xin_zhang@unn01 phones] cat optional_silence.txt
sets.txt
这个文件的每一行是一个phone集合,一般是将同一个音素(包含词位信息 _B _E)存储在同一行,也是为了提供决策树聚类使用的信息
1 2 3 4 5 6 7 [xin_zhang@unn01 phones] head sets.txtA_B AA_E AA_I AA_S AA0_B AA0_E AA0_I AA0_S AA1_B AA1_E AA1_I AA1_S AA2_B AA2_E AA2_I AA2_S
extra_questions.txt
除了决策树自动聚类的问题,我们也可以通过这个文件提供决策树聚类的问题。
1 2 3 [xin_zhang@unn01 phones] head extra_questions.txt B_B B_E B_I B_S CH_B CH_E CH_I CH_S D_B D_E D_I D_S DH_B DH_E DH_I DH_S EH_B EH_E EH_I EH_S ER_B ER_E ER_I ER_S EY_B EY_E EY_I EY_S F_B F_E F_I F_S G_B G_E G_I G_S HH_B HH_E HH_I HH_S IH_B IH_E IH_I IH_S IY_B IY_E IY_I IY_S JH_B JH_E JH_I JH_S K_B K_E K_I K_S L_B L_E L_I L_S M_B M_E M_I M_S N_B N_E N_I N_S NG_B NG_E NG_I NG_S OW_B OW_E OW_I OW_S OY_B OY_E OY_I OY_S P_B P_E P_I P_S R_B R_E R_I R_S S_B S_E S_I S_S SH_B SH_E SH_I SH_S T_B T_E T_I T_S TH_B TH_E TH_I TH_S UH_B UH_E UH_I UH_S UW_B UW_E UW_I UW_S V_B V_E V_I V_S W_B W_E W_I W_S Y_B Y_E Y_I Y_S Z_B Z_E Z_I Z_S ZH_B ZH_E ZH_I ZH_S
比如第一行的问题用自然语言描述就是:”这个phone是不是silence或garbage?”
word_boundary.txt
这个文件指明每个phone的”边界”信息。比如SIL是nonword,而SPN_B是位于词的开始。
1 2 3 4 5 6 [xin_zhang@unn01 phones] head word_boundary.txtbegin end internal
roots.txt
1 2 3 4 5 6 [xin_zhang@unn01 phones] head roots.txtshared split SIL SIL_B SIL_E SIL_I SIL_Sshared split SPN SPN_B SPN_E SPN_I SPN_Sshared split AA_B AA_E AA_I AA_S AA0_B AA0_E AA0_I AA0_S AA1_B AA1_E AA1_I AA1_S AA2_B AA2_E AA2_I AA2_Sshared split AE_B AE_E AE_I AE_S AE0_B AE0_E AE0_I AE0_S AE1_B AE1_E AE1_I AE1_S AE2_B AE2_E AE2_I AE2_Sshared split AH_B AH_E AH_I AH_S AH0_B AH0_E AH0_I AH0_S AH1_B AH1_E AH1_I AH1_S AH2_B AH2_E AH2_I AH2_S
这个文件也是说明怎么对决策树进行聚类。基本跟sets包含的信息一致。
2.2 创建lang目录 Kaldi提供了一个工具来自动的生成lang目录下这些文件:
1 utils/prepare_lang.sh data/ local/dict "<UNK>" data/ local/lang data/ lang
第一个参数是data/local/dict/,这是需要我们提提取准备好的目录, 第二个参数指定OOV对应到哪个词,这里是’ < UNK >’。前面的oov.txt就是根据这个参数生成的。第三个参数data/local/lang是临时的输出目录。第四个参数data/lang就是最终的输出。
所以最终我们需要准备的数据是data/local/dict_nosp:
1 2 [xin_zhang@unn01 s5] ls data/local/dict_nosp.txt lexiconp.txt lexicon_raw_nosil.txt lexicon.txt nonsilence_phones.txt optional_silence.txt silence_phones.txt
nonsilence_phones.txt和silence_phones.txt这两个文件定义了所有的phones
1 2 3 4 5 6 7 [xin_zhang@unn01 dict_nosp] head -3 silence_phones.txt [xin_zhang@unn01 dict_nosp] head -3 nonsilence_phones.txt
lexicon.txt是发音词典:
1 2 3 4 5 6 7 8 [xin_zhang@unn01 dict_nosp] head lexicon.txtA AH0A EY1A ''S EY1 ZA 'BODY EY1 B AA2 D IY0
它告诉我们每个词是由哪些phone组成,我们也可以提供一个lexiconp.txt。lexiconp.txt比lexicon.txt多一列,它的第二列是一个概率值。因为一个词可能有多种发音,但是它们的概率是不同的,所以可以指定概率。我们可以把lexicon.txt看成概率都是1.0。
1 2 3 4 5 6 7 8 9 10 11 [xin_zhang@unn01 dict_nosp] head lexiconp.txt1 .0 SIL1 .0 SPN1 .0 SPNA 1 .0 AH0A 1 .0 EY1A ''S 1 .0 EY1 ZA 'BODY 1 .0 EY1 B AA2 D IY0A 'COURT 1 .0 EY1 K AO2 R TA 'D 1 .0 EY1 DA 'GHA 1 .0 EY1 G AH0
extra_questions.txt
1 2 3 4 5 6 [xin_zhang@unn01 dict_nosp] cat extra_questions.txt B CH D DH EH ER EY F G HH IH IY JH K L M N NG OW OY P R S SH T TH UH UW V W Y Z ZH
lang目录下的文件就是基于这里的extra_questions.txt进行扩充。
utils/prepare_lang.sh脚本有很多参数:
1 2 3 4 5 6 7 8 usage: utils/prepare_lang.sh <dict-src-dir> <oov-dict-entry> <tmp-dir> <lang-dir>/prepare_lang.sh data/ local/dict <SPOKEN_NOISE> data/ local/lang data/ langoptions :default : 5 , #states in silence models.default : 3 , #states in non-silence models.true |false ) # default : true ; if true , use _B, _E, _S & _I markers on phones to indicate word-internal positions.true |false ) # default : false ; if true , share pdfs of all non-silence phones.default : 0.5 [must have 0 < silprob < 1 ]
重要的选项是—share-silence-phones,它默认是false。如果是true,那么所有silence的phone,包括静音、噪声等的pdf(GMM)是共享参数的。
3. 特征提取 基于1 中准备好的音频表单数据,就可以用来提取训练模型所需的特征:
1 2 3 4 5 6 if [ $stage -le 6 ]; thenfor part in dev_clean test_clean dev_other test_other train_clean_100; do /make_mfcc.sh --cmd "$train_cmd" --nj 40 data/ $part exp/make_mfcc/ $part $mfccdir /compute_cmvn_stats.sh data/ $part exp/make_mfcc/ $part $mfccdir
mfcc 特征提取
1 2 3 4 5 6 7 8 9 10 11 steps/make_mfcc.sh sh [options ] <data-dir> [<log-dir> [<mfcc-dir> ] ]e .g.: steps/make_mfcc.sh data/train<log-dir> defaults to <data-dir> /log , and <mfcc-dir> defaults to <data-dir> /data.s: <config-file> # config passed to compute-mfcc-feats.<nj> # number of parallel jobs.to run jobs.write -utt2num-frames <true|false> # If true, write utt2num_frames file .write -utt2dur <true|false> # If true, write utt2dur file .
脚本中最主要的是调用compute-mfcc-feats命令:
1 2 3 4 5 compute-mfcc-featsfiles .options ...] <wav-rspecifier> <feats-wspecifier>
usage 样例:
1 compute-mfcc-feats --config=conf/mfcc.conf scp:data/ train/wav.scp ark:mannually/m fcc/mfcc.ark
查看提取的mfcc特征:
1 copy -feats ark:mfcc.ark ark,t: - | head
特征变换:
1 add -deltas ark:mfcc.ark ark,scp:mfcc-add -deltas.ark,mfcc-add -deltas.scp
特征维度查看:
1 feat-to -dim ark:mfcc.ark -
CMVN 提取:
1 2 3 steps/compute_cmvn_stats.sh[<log-dir> [<cmvn-dir>] ]